理解した気分になる Solaris Internals "Chapter 4: Interprocess Communication" 総ざらえ
FUJIWARA Katsunori <foozy@lares.dti.ne.jp>
How to navigate in this page
- 表示モードの切り替え: t
- 制御表示の切り替え: c
- 次ページ: SPACE, Enter, →, ↓, PageDown, マウスクリック
- 前ページ: ←, ↑, PageUp
- タイトルページ: Home
- 最終ページ: End
- 指定ページ: "ページ数" の入力後に Enter (表紙が 0)
詳細は rst2s5.py での説明参照
4.5. System V Semaphores
[4.5/1-2]
オランダ人の E.W.Dijkstra の発案による Semaphore は、 P (Probeer) 操作と V (Verhoog) 操作から構成されます。
P 操作は semaphore 値を -1 し、 元の semaphore 値が 0 以下の場合はブロックされます。 V 操作は semaphore 値を +1 し、 元の semaphore 値が負値の場合はブロック中の処理を再開します。
4.5. System V Semaphores (続き)
原文では P 操作のことを以下のように言及しているが:
The P operation was the wait, which decremented the value of the semaphore if it was grater than zero
P 操作は (1) 常に semaphore 値を decrement するし (2) wait するのは decrement 前の sempahore 値が 0 以下の場合。後の段落でも以下のように言及:
A zero semaphore value conveys to the calling process that no resources are currently available, and the calling process blocks until another process finishes using the resource and frees it.
※
4.5. System V Semaphores (続き)
ちなみに、 P/V 操作の説明周りは全般的に過去形で記述されているが、 何らかの意図があってのものか? ("Dijkstra 曰く〜" 的な?)
4.5. System V Semaphores (続き)
[4.5/3-4]
有限個の資源をプロセス (or スレッド) 間で排他的に共有したい場合に、 資源の数で初期化した semaphore で同期を行います。 semaphore 値は P 操作で -1, V 操作で +1 され、 P 操作時点で 0 以下なら P 操作は block されます。
Solaris では semget(2) での semaphore 生成時の第2引数で、 同時に生成する semaphore の数を指定可能です。
4.5.1. Semaphore Kernel Resources
[4.5.1/1-5]
semaphore 周りのカーネルチューニングパラメータとして、 表 4.6 で列挙されたものが指定可能。
詳細は以下の通り。
project.max-sem-ids: プロジェクト毎の最大 semaphore ID 数 process.max-sem-nsems: semget(2) で指定可能な semaphore 数の上限 process.max-sem-ops: semop(2) 呼び出しで指定可能な操作数の上限
4.5.2. Kernel Implementation of System V Semaphores
[4.5.2/1]
(他の SystemV IPC 系機能と同様に) 初回の semaphore 初期化処理の実行契機で、 カーネルモジュール /kernel/sys/semsys がロードされます。 semaphore の最大数は 65,536 個です。
4.5.3. Semaphore Operations
[4.5.3/1]
semaphore set は semget(2) で生成され、 semid_ds 構造体を使って表現されます。
※ 原文の semds_id は semid_ds の typo
4.5.3. Semaphore Operations (続き)
ユーザ空間とカーネル空間での情報受渡し用構造体の定義
- semid_ds in <sys/sem.h>
- semid_ds32 in <sys/sem_impl.h>
- semid_ds64 in <sys/ipc_impl.h>
カーネル内部の管理情報用構造体の定義
ksemid in <sys/sem_impl.h>
kipc_perm_t (= Solaris SysV IPC 共通の ID 管理構造体) を拡張した管理構造体。
4.5.3. Semaphore Operations (続き)
構造体 ksemid
MDB の情報取得/表示等向けユーザ空間実装等は、 カーネルの内部情報をまるごと取り出す必要があるため、 この構造体を使用。
構造体 semid_ds32, semid_ds64
ユーザ空間とカーネル空間での情報受渡し用の両構造体は、 _LP64 定義の有無に応じた semid_ds と同等。
但し semid_ds64 には何故か カーネル内アドレス参照を保持する sem_base フィールドが無い。
shmid_ds や msqid_ds でも同様に、 xxxid_ds64 では主にカーネル内アドレス参照周りが "実装依存情報" として省略されている。
4.5.3. Semaphore Operations (続き)
[4.5.3/2-3]
semget(2) で生成される semaphore へのアクセス権限は、 owner, group および other に対して、 READ および ALTER の可否をそれぞれ指定可能です。
semaphore の新規作成時は、 初期化された semid_ds 中の sem_base フィールドが、 新規に割り当てられた semaphore set 情報領域を参照します。
4.5.3. Semaphore Operations (続き)
semget(2) のオンラインマニュアル曰く、 「アクセス権限ビットマスクは semflg 引数で指定可能」。
SystemV IPC 系の固有フラグ値は 01000 以上の値なので、 0000 から 0777 の範囲に収まる POSIX でのアクセス権限ビットマスク定義マクロがそのまま使用可能。 但しその旨の言及はまったく無いので、 「知っている人 (or "access permission bits" で察することができる人) しか使うなよ」感が溢れている。
4.5.3. Semaphore Operations (続き)
そもそも semget(2) のオンラインマニュアルにおいて、 実装の内部事情である semid_ds 構造体のフィールド sem_perm, sem_nsems, sem_otime, sem_ctime に関する言及が何の前置きも無く記載されている点で、 「知っている人しか使うなよ」感が MAX なのだけど……
4.5.3. Semaphore Operations (続き)
[4.5.3/4-7]
semaphore に対する初期化や変更、情報参照は semctl(2) で行います。
アプリケーションロジックにおける P/V 操作には semop(2) を用います。
semop(2) に対する sem_op 指定は、 非ゼロであれば semaphore に対する P/V 操作を、 ゼロであれば semaphore 値の読み取りを意味します。
詳細は semop(2) のオンラインマニュアルを参照してください。
4.5.3. Semaphore Operations (続き)
semop(2) に対する sem_op 指定は、 実際に使う段にならないと読む気にならないほど複雑……
4.6. System V Message Queues
[4.6/1]
"message queue" は Solaris システム上のプロセス間での、 可変サイズの非同期メッセージ交換機能を提供します。 キー値とフラグを伴う msgget(2) 呼び出し契機で、 一旦 message queue が割り当てられたなら、 msgsend(2) で送信されたメッセージは msgrecv(2) が実施されるまで FIFO queue にて保持されます。
4.6. System V Message Queues (続き)
[4.6/2]
メッセージが保持可能な "type" 値に関して、 カーネルは何ら事前の想定や定義を持ちませんが、 アプリケーション実装においてこのフィールド値は、 優先順位や受け取り手の制御に使用することもできます。
4.6. System V Message Queues (続き)
[4.6/3]
msgctl(2) によって、 message queue への権限設定や、 message queue 自体の破棄が可能です。 強制指定の shutdown や reboot 以外では "an empty and unused" な message queue は破棄されないので、 綺麗なアプリケーション終了手順を実現するのに用いることも可能です。
以下の記述に関して、 該当するマニュアル記述や実装コードが特定できなかった :-<
system will not remove an empty and unused message queue unless it is explicitly instructed to do so or the system is rebooted
4.6. System V Message Queues (続き)
ゾーン終了時に関連リソースを破棄できるように、 カーネルモジュールのロード契機での zone_key_create() 呼び出しの際に msg_remove_zone() を登録している: ここから間接的に ipc_remove_zone() が呼び出される。
登録された shutdown コールバック (struct zsd_entry の zsd_shutdown フィールド経由) がゾーン終了時に呼ばれる際のゾーン管理コード側でも、 IPC 共通処理の ipc_remove_zone() 側でも、 特に何らブロック要否判定をしていないように見える。
この「強制終了」はゾーン固有? それとも終了抑止判定を見落としている?
ゾーン繋がりで更に脱線:
登録 key 群に関する shutdown/destroy コールバック呼び出しには、 ユーティリティ関数 zone_zsd_callbacks() が使用される。
zone_zsd_callbacks() は処理種別指定として ZSD_SHUTDOWN あるいは ZSD_DESTROY のいずれかを 単独で 受け付けるが、 関数末尾で 両方 のコールバックを順次呼び出している (zsd_apply_*() は対象コールバック呼び出しのユーティリティ)。
static void zone_zsd_callbacks(zone_t *zone, enum zsd_callback_type ct) { ASSERT(ct == ZSD_SHUTDOWN || ct == ZSD_DESTROY); .... snip .... /* Now call the shutdown and destroy callback for this key */ zsd_apply_all_keys(zsd_apply_shutdown, zone); zsd_apply_all_keys(zsd_apply_destroy, zone); }
コールバック呼び出しが以下の手順で実施されることで、 上記のような実装でも期待したコールバックが呼び出される。
- ct 値に応じて zsd_flags フィールドに ZSD_SHUTDOWN_NEEDED または ZSD_DESTROY_NEEDED ビットを立てる (※ これは zone_zsd_callbacks() 側で実施)
- zsd_apply_shutdown() や zsd_apply_destroy() は zsd_flags フィールドの対応ビットが立っている場合のみ、 コールバック呼び出し処理を実施
- コールバック呼び出し後は zsd_flags フィールドの当該ビットをクリア
zsd_apply_shutdown() と zsd_apply_destroy() は、 zsd_flags フィールドの確認対象ビットや、 コールバック関数の取得フィールド、 statistics の記録対象等を除けば、 ほぼ同一のコードで構成されている。
もうちょっとやりようがある気がするが、 歴史的経緯でこうなったのかな?
もしも比較的初期からこのような実装だとして、 二〇世紀時分なら、 マクロで記述を共通化 (= ソース記述量の削減) するとか、 可変部分をパラメータ化 (= バイナリサイズの削減) したりしてたんだろうなぁ :-)
4.6.1. Kernel Resources for Message Queues
[4.6.1/1]
先述した IPC 機能と同様に message queue 機能は動的に読み込まれる /kernel/sys/msgsys モジュールによって提供されます。
余談になるが、 4.5.1. は "Semaphore Kernel Resources" なのに 4.6.1. は "Kernel Resources for Message Queues" なのは何故なのか (担当筆者が違うにしても、章立てぐらいは揃えるような気が……)
msgget(2) 実装は通常のシステムコール類と同様の usr/src/uts/common/syscall 配下 ではなく usr/src/uts/common/os/msg.c で記述されている。
SystemV IPC 機能の一部である message queue のシステムコール群は、 msgget(2) 等の呼び出し契機でのモジュール読み込みを実現するため、 *.o ファイルの持つ struct modlinkage から struct modlsys → struct sysent を経て参照される msgsys() 関数経由で呼ばれるようになっている。
そのため、 msgget(2) のユーザ空間側実装の実体は 機能識別子 (e.g. MSGGET, MSGCTL, etc) を伴った msgsys システムコール呼び出しとなっている。
/* in usr/src/lib/libbc/libc/sys/common/msgsys.c */ int msgget(key_t key, int msgflg) { return (_syscall(SYS_msgsys, MSGGET, key, msgflg)); }
4.6.1. Kernel Resources for Message Queues (続き)
[4.6.1/2-5]
表 4.7 に利用可能なカーネルチューニングパラメータを列挙します。
- project.max-msg-ids
- プロジェクト毎の最大メッセージキュー ID 数。 上限超過時の msgget(2) には ENOSPC を返却。
- process.max-msg-qbytes
- メッセージキュー上のメッセージ群の総バイト数。 msgsnd(2) によるメッセージ送信によって、 キュー上のメッセージ群の総バイト数が上限値を超える場合、 エラー返却か領域空き待ちでブロック。
- process.max-msg-messages
- メッセージキュー上の総メッセージ数。
project.max-msg-ids 相当の制約は、 以前はシステムワイドに単一の上限値だった模様。 ('previously returned when ".... limit on the maximum number of allowed message queue identifiers systemwide would be exceeded"')
project.max-msg-ids 値の確定処理部分の実装を見るに、 旧来の設定値 msgsys:msginfo_msgmni が指定された場合も、 rctl_add_legacy_limit() 経由で反映されるのかな?
/* from project_init() in usr/src/uts/common/os/project.c */ rc_project_msgmni = rctl_register("project.max-msg-ids", RCENTITY_PROJECT, RCTL_GLOBAL_DENY_ALWAYS | RCTL_GLOBAL_NOBASIC | RCTL_GLOBAL_COUNT, IPC_IDS_MAX, IPC_IDS_MAX, &project_msgmni_ops); rctl_add_legacy_limit("project.max-msg-ids", "msgsys", "msginfo_msgmni", 128, IPC_IDS_MAX);
msgsys:msginfo_msgmni の廃止は Solaris 10 リリース契機 ( https://docs.oracle.com/cd/E24845_01/html/819-0376/appendixa-6.html )
rctl_* は Resource ConTroL 系機能のプレフィックスで、 関連する定義は usr/src/uts/common/os/rctl.c および usr/src/uts/common/sys/rctl.h を参照。
rctl_register() の第2引数は設定値の通用範囲で、以下の値が設定可能。
- RCENTITY_PROCESS
- RCENTITY_TASK
- RCENTITY_PROJECT
- RCENTITY_ZONE
max-msg-qbytes 上限値設定は、 リソース管理の分類上は "プロジェクト毎" になっているが、 実装上の判定処理は以下のように "メッセージキュー毎" の管理になっている。
- プロセス毎の max-msg-qbytes 上限値は、 プロセス生成時点の設定内容で初期化 (proc_t.p_rctls からリンク)。
- メッセージキュー毎の上限値 msg_qbytes は:
- キュー生成時に process.max-msg-qbytes で初期化
- IPC_SET 指定の msgctl(2) 呼び出しで事後更新可能
- 実施時点の msg_qbytes 値超過ならエラー
- 実施プロセスの max-msg-qbytes 値超過ならエラー
- msgsnd(2) のサイズ上限確認はキュー毎の設定値 (+ 当該時点の消費量) を使って判定
- メッセージ送信時における空き領域不足エラー時の挙動は、
メッセージサイズとキュー毎の上限値 msg_qbytes との大小関係で異なる
- 上限値超過の場合は EINVAL
- 上限値以下 (= 領域空き待ち) の場合は EAGAIN (or IPC_WAIT 指定アリなら空き待ちでブロック)
4.6.1. Kernel Resources for Message Queues (続き)
max-msg-qbytes および max-msg-messages は 「プロセス毎」分類とはイマイチ馴染まない気がするが、 とりあえず「システムワイド」系は「プロセス毎」分類にしたのかな?
4.6.1. Kernel Resources for Message Queues (続き)
[4.6.1/6-7]
/kernel/sys/msgsys 読み込み契機での初期化処理は、 共有メモリやセマフォ等の初期化処理と概ね同様です。
メッセージキュー毎のカーネルデータ構造は msqid_ds 構造体です。
4.6.1. Kernel Resources for Message Queues (続き)
セマフォ同様に以下のような msqid_ds 類似構造体が定義されている。
- ユーザ空間とカーネル空間での情報受渡し用構造体の定義
- msqid_ds in <sys/msg.h>
- msqid_ds32 in <sys/msq_impl.h>
- msqid_ds64 in <sys/ipc_impl.h>
- カーネル内部の管理情報用構造体の定義
- kmsqid in <sys/msg_impl.h>
4.6.2. Kernel Implementation for Message Queues
[4.6.2/1-3]
メッセージキューの生成とメッセージの送受信における 主要なケースでのカーネル処理フローをウォークスルーします。
- メッセージ生成側での msgget(2) 契機でのカーネル処理 ipc_get() によりメッセージキュー毎の ipc_perm 領域が確保
- 呼び出し側プロセスの UID/GID と呼び出し引数に応じて ipc_perm 領域を初期化
4.6.2. Kernel Implementation for Message Queues (続き)
原文中で言及されている IPC_ALLOC ビットは、 IPC オブジェクト初期化 (の終段処理) のユーティリティ関数 ipc_commit_begin() で ON になり、 IPC オブジェクト破棄のユーティリティ関数 ipc_remove() で OFF になる。
ipc_get() で引き当てた ipc_perm 領域 (を先頭に含む各 IPC 固有構造体) の IPC_ALLOC ビットが OFF なら、 新規割り当てとみなして領域の初期化コードが実行される。
4.6.2. Kernel Implementation for Message Queues (続き)
[4.6.2/4-8]
msgsnd(2) 呼び出し側のアプリケーションロジックは、 種別やボディを指定してメッセージを生成します。
- ユーザ空間からカーネル空間にメッセージをコピー
- メッセージ送受信数等の稼働状況統計情報を更新
- 送信側プロセスの権限をチェック
- 残りの処理は疑似コードを参照
4.6.2. Kernel Implementation for Message Queues (続き)
ユーザ空間からカーネル空間へのメッセージコピー (copy-in) は、 厳密には以下のような実装になっている。
- サイズが MSG_PREALLOC_LIMIT 以下なら ipc_lookup() に先行してメモリ確保
- それ以外の場合は送信可能化待ち (= max-msg-qbytes 周りの判定) の後でメモリ確保
前者の処理は Solaris10 以降で取り込まれた対処 (識別番号 "6485031")。
- pros: ipc_lookup() 以降の処理で排他周りの処理を低減可能
- cons: キューの引き当てや権限チェック等でのエラー時にオーバヘッドが増加
判定基準値 MSG_PREALLOC_LIMIT の定義は即値指定で 8192。
このサイズは実運用での知見に基づくもの?
もしも「Slab アロケータならエラー時ペナルティのオーバヘッドも少ない」 想定の元でエイヤ!で決めたものなら、 稼働先アーキテクチャのページサイズ PAGESIZE (SPARC なら 8192、x86 なら 4096) を使った方が良いかも?
4.6.2. Kernel Implementation for Message Queues (続き)
原文の処理手順に関する記述では、 「権限チェック (ipcperm_access())」 ⇛ 「ipc_lookup() 呼び出しで始まる疑似コード」だが、 実コードでは ipcperm_access() よりも ipc_lookup() の方が先。
権限設定がメッセージキュー毎であることを考えると当然といえば当然 (笑)
4.6.2. Kernel Implementation for Message Queues (続き)
疑似コードでは、 メッセージキューの引き当てに失敗した場合は EIDRM エラー返却となっているが、 指定キュー不在周りの実装は以下のようになっている (後者は疑似コードでの記載通り)。
- ipc_lookup() での引き当て失敗 ⇛ EINVAL
- メッセージ処理待ち (max-msg-qbytes 等に由来する休止) から復帰した際の当該キュー無効検出 ⇛ EIDRM
msgsnd(2) のオンラインマニュアルの記載も上記実装に沿っている。
変更履歴上でも初版から上記挙動になっているので、 仮に原文疑似コードのような実装の時期があったとしても、 Solaris10 よりも前の版での話の筈。
4.6.2. Kernel Implementation for Message Queues (続き)
[4.6.2/9-]
4.7. POSIX IPC
[4.7/1]
POSIX の API 標準化によって、 System V IPC と同等の機能の業界標準 I/F が策定されましたが、 同様な形式ではあっても両者の実装は大きく異なります。
4.7. POSIX IPC (続き)
[4.7/2]
(Solaris における) POSIX IPC は、 既存の IPC を元にユーザランド上に実装されています。 また、実ファイルのファイル名に対する ftok(3C) 適用で生成された「キー」によって、 操作対象を識別していた System V IPC に対して、 POSIX IPC では実在ファイルと直接対応する必要のない "POSIX IPC name" という抽象化された名前で操作対象を識別します。
4.7. POSIX IPC (続き)
[4.7/3-4]
POSIX IPC 固有のカーネルチューニングパラメータは存在せず、 プロセス毎のファイル open 数やメモリ空間サイズの上限が、 潜在的な制限要素となります。
表 4.8 に POSIX IPC の API 一覧を提示します。
4.7. POSIX IPC (続き)
[4.7/5]
Solaris においては、 POSIX message queue や POSIX semaphore の実装は XXX_open() 系関数が返したファイルディスクリプタを使って mmap(2) を行いますし、 POSIX shared memory API 利用者は明示的な mmap(2) 呼び出しの必要があるなど、 POSIX IPC 機能はメモリマップドファイルをベースに実装されています。
4.7. POSIX IPC (続き)
[4.7/6]
ファイル等をプロセスのアドレス空間に貼り付る際に mmap(2) は private と shared を選択しますが、 POSIX IPC 機能の実装は shared での貼り付けをベースにしています。
4.7.1. POSIX Shared Memory
[4.7.1/1]
同じ POSIX IPC name で呼び出した shm_open() の戻り値 (= file descriptor) を使って mmap(2) を実施することで、 異なるプロセスの間で同じメモリセグメントを共有することができます。 当該メモリセグメントへの書き込みは、 mmap(2) 対象のファイルに書き出されるため、 共有したプロセス間で参照可能になります。
4.7.1. POSIX Shared Memory (続き)
[4.7.1/2]
Solaris の shm_open() 実装は、 "POSIX IPC name" に (間接的に) 対応したファイルに open(2) を発行し、 shm_unlink() 実装は当該ファイルに unlink(2) を発行するので、 最後の shm_unlink() 契機で "POSIX IPC name" に (間接的に) 対応したファイルは破棄されます。
4.7.1. POSIX Shared Memory (続き)
※ POSIX IPC name と "(間接的に) 対応したファイル" の関係について、 実装コードベースでの詳細調査結果があるのだが、 スライド形式では説明が難しいので、 t キーで表示モードを切り替えて地の文を参照のこと。
Solaris の POSIX IPC 処理は、 操作対象オブジェクト名 (ObjectName) が指定された場合、 基本的に /tmp/(ObjectType)(ObjectName) ファイルを生成しようとする。
ここでの (ObjectName) は、 以下の条件を満たす "POSIX IPC name" から、 先頭の "/" を除外したものを指すものとする。
The first character of name must be a slash (/) character and the remaining characters of name cannot include any slash characters
(from man shm_open(3C) 他)
ちなみに POSIX IPC name の可搬性に関しては、 Solaris ではいずれの POSIX IPC API でも以下のように記載されている一方で:
For maximum portability, name should include no more than 14 characters, but this limit is not enforced.
Linux では可搬性に関しては一切言及されておらず、 且つ API 毎に上限値が異なる (semaphore とそれ以外)。
- shm_open(): "up to NAME_MAX (i.e., 255) characters"
- sem_open(): "up to NAME_MAX -4 (i.e., 251) characters"
- mq_open(): "up to NAME_MAX (i.e., 255) characters"
閑話休題
(ObjectType) は IPC オブジェクトの種別を示す文字列で、 以下のような文字列が使用される。
- for shared memory:
- .SHMD: data ファイル
- .SHML: lock ファイル
- for semaphore:
- .SEMD: data ファイル
- .SEML: lock ファイル
- for message queue:
- .MQD: data ファイル
- .MQP: permission ファイル
- .MQN: DSCN (?) ファイル
- .MQL: lock ファイル
Note
(ObjectType) が拡張子/接尾辞 (suffix) ではなく接頭辞 (prefix) として使用されているのは、 /tmp 配下にファイルを生成した際に ls 等でのデフォルト除外対象にしたいためか?
(後述する) ハッシュ値を用いた中間ディレクトリ階層を作成する際に、 ディレクトリ名冒頭に "." を使用しているのも同じ理由と思われる。
先述したパス形式の場合、 (ObjectType) の連結が発生するため、 (ObjectType)(ObjectName) 部分がファイル名の長さ制限 (POSIX の pathconf で言うところの _PC_PATH_MAX ではなく _PC_NAME_MAX の方) に抵触してしまう可能性がある。
そのようなケースにおいて Solaris の POSIX IPC 機能群は、 生成するファイルのパスを /tmp/.(HashOfName)/(ObjectType)/(ObjectName) 形式に切り替えるようになっている。
(HashOfName) は (ObjectName) の MD5 ハッシュ値。 MD5 ハッシュ値が衝突するケースでも操作対象に対応するパスが一意になるように、 .(HashOfName)/(ObjectType) ディレクトリ配下に改めてファイル (ObjectName) ファイルを生成している。
これらの一連の処理は以下の内部関数の組み合わせで実現される。
- __pos4obj_check(): IPC オブジェクト名の形式チェック
- __pos4obj_name(): IPC オブジェクト名から実際のファイルパスを確定
- __pos4obj_unlink(): IPC オブジェクト名に対応するファイルの削除 (+ 空の場合は中間階層も破棄)
Note
例えば shm_open(3C) の処理の場合、 以下の内部関数呼び出しの都度 __pos4obj_name() による対応ファイルパスの確定が実施される。
- lock ファイル生成 (__pos4obj_lock(path, SHM_LOCK_TYPE))
- data ファイル生成 (__pos4obj_open(path, SHM_DATA_TYPE, ...))
- lock ファイル破棄 (__pos4obj_unlock(path, SHM_LOCK_TYPE))
MD5 ハッシュ値算出を伴うケースでの実行効率を考えた場合、 少なくとも「ファイル名の導出」に関しては、 IPC API 呼び出し毎に1回の実施で済むように工夫すべき気が……
なお、 MD5 ハッシュ値算出が必要ないケースにおいて MD5 ライブラリへの依存/読み込みが生じないように、 共有ライブラリ libmd5.so の読み込みには dlopen(3C) を使った明示的な読み込みを行う、 といった効率化は実装されている。
Note
__pos4obj_unlink() による "空の場合は中間階層も破棄" は、 内部関数 __pos4obj_clean() において以下のように実現されている。
- 冒頭の /tmp/ 部分以外に "/" を含まない場合は即処理終了
- 末尾側最初の "/" を "0" で置換 (= /tmp/.(HashOfName)/(ObjectType) の抽出)
- errno を保存
- 中間ディレクトリを rmdir(2) で破棄 (※ 戻り値は無視)
- 末尾側二番目の "/" を "0" で置換 (= /tmp/.(HashOfName) の抽出)
- 中間ディレクトリを rmdir(2) で破棄 (※ 戻り値は無視)
- errno を復旧
なお __pos4obj_name() は、 (ObjectType)(ObjectName) 部分が _PC_NAME_MAX 制約に抵触する場合における中間ディレクトリ階層 (= .(HashOfName)/(ObjectType) ディレクトリ) の生成も受け持っている。
これらの中間ディレクトリ階層は、 オーナー以外でも参照できるようにモード 0777 = drwxrwxrwx で生成される。
セキュリティ的にどうよ?という気がしないでもないが……
中間ディレクトリ階層の読み書きが全ユーザに許可されている場合、 例えば以下のような攻撃手法が使える筈。
- Alice が /tmp/.deadbeaf/*/loooongobjectname ファイル群を生成
- Mallory が /tmp/.deadbeaf/*/loooongobjectname ファイル群を、 モード 0666 = -rw-rw-rw- な自身の所有するファイル群で差し替え
- Bob が /tmp/.deadbeaf/*/loooongobjectname 経由でメッセージを送信
- Mallory は自身が所有者である /tmp/.deadbeaf/*/loooongobjectname ファイル群へアクセス可能
- Mallory は Bob のメッセージを盗聴
Note
本来のファイル群へのアクセス権限がないのであれば、 Mallory から Alice に対して (改竄された) メッセージの送信はできないので、 Man-In-The-Middle (MITM) は成立しない。
アクセス権限があるのであればその時点で既に in-secure。
POSIX IPC を利用する「サービス」を停止に追い込むだけなら、 ここまで面倒なことをしなくても、 対応するファイル/ディレクトリを適当に削除することで実現可能。
いわゆる sticky bit を使った不正な削除/改名からの保護をしようとした場合、 IPC オブジェクトに対応するファイル群を初期化したプロセスと同じ UID 権限を持つプロセスでないと、 これらのファイル群の刈り取りを行うことができなくなってしまう、 という問題が……
Note
ちなみに lock ファイルの生成は以下の手順で実施される。
- 排他指定 (O_EXCL) 付きで lock ファイルを生成
- lock ファイル生成成功時は正常終了
- EEXIST 以外のエラーならエラー終了
- sleep() での 1sec 休止後に再度 lock ファイル生成を実施
- 繰り返し上限 ("64" がハードコーディング) を超えたらエラー終了
Solaris の以下のソース中に、 先行して実装された POSIX Semaphores 向けコードを元に、 POSIX Shared Memory 向けコードが実装された (or リファクタリングされた) と思しきコピー&ペーストの痕跡あり。
/* * from sem_open() in usr/src/lib/libc/port/rt/sem.c * for POSIX Semaphores */ /* acquire **semaphore** lock to have atomic operation */ if (__pos4obj_lock(path, SEM_LOCK_TYPE) < 0) return (SEM_FAILED); /* * from shm_open() in usr/src/lib/libc/port/rt/shm.c * for POSIX Shared Memory */ /* acquire **semaphore** lock to have atomic operation */ if (__pos4obj_lock(path, SHM_LOCK_TYPE) < 0) return (-1);
4.7.1. POSIX Shared Memory (続き)
Solaris の System V shared memory 実装は、 カーネル内の anonymous memory を介した共有なので、 プロセス異常終了等で smctl(IPC_RMID) による破棄が無くても OS の再起動契機で内容が破棄される。
その一方で POSIX shared memory 実装は、 "POSIX IPC name" に (間接的に) 対応したファイル (e.g. /tmp/.SHMDfoobar) を介した共有なので、 shm_unlink() による明示的な破棄をしそこなった場合、 OS の再起動を跨いで内容が保持される可能性がある (筈)。
4.7.1. POSIX Shared Memory (続き)
今日では /tmp にはメモリベースの tmpfs を使用するのが一般的なので、 実運用上は OS 再起動契機を跨いでの永続性はないと思われる。
しかし /tmp にストレージをマウントしているようなケースでは、 OS 再起動を跨いだ永続性が生じてしまう。 (HPC 系システムでは /tmp 消費によるメモリ枯渇を回避するために、 そういう構成があったと記憶している)
POSIX IPC 仕様とし「OS 再起動を跨いだ永続性」が、 想定範囲/許容範囲なのかは要確認。
4.7.2. POSIX Semaphores
[4.7.2/1]
POSIX IPC name で識別される named semaphore は sem_open() で、 名前を持たない unnamed sempahore は sem_init() で初期化されます。 後者は Solaris threads library が提供する API を元に実装されています。 表 4.9 は Solaris が提供する semaphore 関連 API の一覧です。
Table 4.9 中の "Manual Section" 情報は、 現行の最新版 (on OpenIndiana) からは乖離している模様: System V IPC 系以外は全て "3C" セクション扱い。
4.7.2. POSIX Semaphores (続き)
[4.7.2/2]
sem_wait(), sem_trywait(), sem_post() および sem_getvalue() は named/unnamed どちらの semaphore に対しても適用可能な機能ですが、 生成/破棄の API はそれぞれ別の API を使用します。
4.7.2. POSIX Semaphores (続き)
Solaris Internals 原文曰く、 POSIX semaphore API は 同名の Solaris threads library を "jump-table mechanism in the Solaris POSIX library" 経由で呼び出す、とのことだが、 肝心の "jump-table mechanism" が見当たらない。
usr/src/lib/libc/port/rt/sem.c ファイルで定義されている POSIX semaphore 関数群は、 Solaris threads library の関数 (sema_YYYY()) を直接呼び出しており、 間接的な呼び出しは見られない (Solaris Internals の記述は旧版の名残か?)。
⇛ Solaris 8 時点の実装に関する記述がそのままコピペされた模様 (by yokoyama)
4.7.2. POSIX Semaphores (続き)
[4.7.2/3]
named semaphore を初期化する sem_open() が返す sem_t 構造体領域には、 利用可能資源数 sem_count, 通用範囲種別 sem_type (USYNC_THREAD or USYNC_PROCESS), マジックナンバ sem_magic が保持されています。 プラットフォーム毎の実装固有情報は padding 領域に保持されます。
4.7.2. POSIX Semaphores (続き)
[4.7.2/4-5]
使用中の POSIX named semaphore は semaddr 構造体を使った単方向リストで各プロセス毎に管理されています。
semaddr 構造体による管理リストは、 カーネル空間ではなくユーザ空間に保持されており、 連結用ポインタ sad_next, POSIX IPC name sad_name, sem_t 構造体ポインタ sad_addr, 対応ファイル inode 値 sad_inode が保持されています。
4.7.2. POSIX Semaphores (続き)
[4.7.2/6-10]
(以下 sem_open() 契機での named semaphore 初期化処理フロー)
- __pos4obj_lock() でロックファイル生成
- __pos4obj_open() で内部ファイルを open(2)
- 新規 semaphore なら ftruncate() で当該ファイルを sem_t 構造体と同じ長さにリサイズ
- 当該 semaphore がファイルシステム上に既に存在する場合、 IPC name (= semaddr.sad_name) と inode 値 (= semaddr.sad_inode) が一致する semaddr 構造体が semheadp リスト中に存在するか確認
- 存在する場合は当該 semaddr が指す sem_t 領域を再利用
4.7.2. POSIX Semaphores (続き)
inode 値を併用することで、 一見すると対象ファイルの一致確認の厳密性が確保されたような気になるが、 一般的なファイルシステムだと inode 値はかなり容易に再利用されるので、 実はこの手法は安全性の向上にはそれほど寄与しない。
Mercurial ではファイル更新時の安全性のために、 外部データファイルを書き出す多くのケースで (userland ベースの) Copy-on-Write を実施している。
"inode 値の即時再利用性" が Copy-on-Write の組み合わせは、 以下のような問題発生の頻度を増加させる可能性があることが判明。
"同一 UTC 秒内" に "st_size が元に戻る" ような変更が複数回実施された際に、 inode 値が再利用されてしまう (可能性がある) と、 標準的な stat_t 情報 (size, ctime, mtime, inode etc..) のみでは、 メモリに読み込んだ外部ファイルの内容 (= cache) の妥当性判定ができなくなってしまう
最終的に以下のような方法で問題を回避することに。 (詳細は Exact Cache Validation Plan - Outline of issue 参照)
外部データファイルを書き出す際に st_ctime が以前と同一になったなら、 st_mtime を明示的に +1 だけ未来に進める
4.7.2. POSIX Semaphores (続き)
[4.7.2/11]
Solaris の POSIX named semaphore 機能実装では、 ロックファイルや semaphore データ共有用ファイルを /tmp 配下に生成します。
内部的なファイル生成周りに関する詳細は、 "4.7.1. POSIX Shared Memory" での説明参照。
4.7.2. POSIX Semaphores (続き)
[4.7.2/12-14]
新規の POSIX named semaphore 生成後の処理フローは以下の通りです。
- 管理情報を保持する semaddr 領域の生成、 内部ファイルを sem_t 領域として mmap(), sema_init() での sem_t 領域の初期化を実施
- sema_init() は指定パラメータを元に sem_count, sem_type, sem_magic を含む sem_t 構造体領域を初期化
相変わらず "jump-table mechanism" 経由で云々の記述あり。
4.7.2. POSIX Semaphores (続き)
[4.7.2/15]
Solaris では sem_t 構造体の padding 領域を、 内部的なスレッド間同期処理で使用するための mutex や condvar として使用します。
4.7.2. POSIX Semaphores (続き)
[4.7.2/16-18]
POSIX IPC の named semaphore で想定されている残りの操作は以下のものです。
- sem_close() によって、 プロセス内で管理情報を保持する semaddr 領域 (by free(3C)) や、 semaphore 情報を保持する sem_t 領域 (by munmap(2)) を解放 (close 後も semaphore 情報が書き出された実ファイルは存在し続けます)
- sem_unlink() によって、 semaphore 情報が書き出された実ファイルへの unlink(2) が実施
4.7.2. POSIX Semaphores (続き)
Solaris Internals では POSIX named semaphore の解説に終始していて、 その実現の基礎となっている Solaris threads library semaphore の実装や、 POSIX unnamed semaphore に関しては殆ど言及がない。
Solaris Internals の記述を離れて、 個人的に内部実装を調べた結果を以下にまとめる。
4.7.2. POSIX Semaphores (続き)
POSIX の "unnamed semaphore" は、 POSIX IPC name のような識別情報を使用しないので、 semaphore の仕組みの範疇ではプロセス間での共有ができない。
そのため、 「プロセス内スレッドの同期」か、 以下のような 「 semaphore の仕組みの外 経由での sem_t 領域の共有」 を想定している。
- 別途明示的に確保した shared memory 領域経由での共有
- fork() で生成された子プロセス (群) との間での共有
4.7.2. POSIX Semaphores (続き)
sem_init() の引数 pshared の値が非ゼロ (= プロセス間共有あり) であっても、 管理情報を保持する sem_t 構造体が shared memory 上に 無い 場合は、 そもそもプロセス間での semaphore 情報の共有はできない。
そのため、 Linux での sem_init 実装は pshared 引数値を見ていないらしい 少なくとも以前の版はそうであった旨を、 ソースコードを添えて言及しているウェブページあり (GNU/Linux でのスレッドプログラミング 参照)。
4.7.2. POSIX Semaphores (続き)
一方 Solaris threads library (= Solaris の POSIX IPC 実装の実体) では、 pshared 値から算出した type 情報を元に、 例えば sema_wait() 実装で以下のように処理を切り分けている。
if (lsp->type == USYNC_PROCESS) { /* 「プロセス間共有」あり */ lwp_sema_timedwait(...); /* カーネル処理に移行 */ } else if (/* 単独スレッドなプロセス */ !curthread->ul_uberdata->uberflags.uf_mt && /* 利用可能資源が非ゼロ */ lsp->count != 0) { /* 直接 lsp->count を操作 */ } else { /* 複数スレッドなプロセス、又は count が 0 */ /* 「count が非ゼロになるまで sleep」の繰り返し */ }
sema_wait() での処理の切り分けにおいて、 「単独スレッドなプロセス」で且つ「semaphore 値がゼロ」な状況は、 明らかにデッドロックする のでは? ⇛ 単一スレッドでの処理であっても 「signal ハンドラ契機でリソース開放」 ならブロック状態から抜け出せるケースを見落としていた!
4.7.2. POSIX Semaphores (続き)
sem_t.sem_magic フィールドの初期化/更新 (= クリア) は、 Solaris threads library 側で実施されるが、 この値の評価を行っているのは POSIX semaphore 実装コード側のみ。
4.7.2. POSIX Semaphores (続き)
POSIX semaphore 実装向け内部関数 sem_invalid() (in usr/src/lib/libc/port/rt/sem.c) における sem_t.sem_magic != SEMA_MAGIC 判定処理に対するコメントが、 若干投げやりな感じ (笑)
SUSV3 requires ("shall fail") an EINVAL failure for operations on invalid semaphores, including uninitialized unnamed semaphores. The best we can do is check that the magic number is correct. This is not perfect, but it allows the test suite to pass. (Standards bodies are filled with fools and idiots.)
4.7.3. POSIX Message Queues
[4.7.3/1-2]
Solaris における POSIX message queue 実装でのデータ構造概要を、 図 4.5 に示します。
本章では、 queue を利用可能にする mq_open(), message の送受信を行う mq_send() および mq_receive() といった message queue の根幹をなす機能の説明に焦点を当てます。
4.7.3. POSIX Message Queues (続き)
[4.7.3/3]
message queue の生成時には、 総サイズ (mq_totsize), メッセージ最大サイズ (mq_maxsz), キュー毎最大メッセージ数 (mq_maxmsg), 未読メッセージ数 (mq_current), メッセージ待ちスレッド数 (mq_waiters), 現行最大優先度 (mq_curmaxprio) などの情報を管理する "message queue header" が作成されます。
4.7.3. POSIX Message Queues (続き)
[4.7.3/4]
message queue の属性値のいくつかは、 mq_open() (初期化時) や、 mq_setattr() (初期化後) 経由で変更可能です。
4.7.3. POSIX Message Queues (続き)
Linux のオンラインドキュメント (man mq_overview) における message priority に対する言及曰く:
On Linux, sysconf(_SC_MQ_PRIO_MAX) returns 32768, but POSIX.1 requires only that an implementation support at least priorities in the range 0 to 31; some implementations provide only this range.
Solaris は _MQ_PRIO_MAX が 32 なので、 "some implementations" に相当する。
4.7.3. POSIX Message Queues (続き)
実ファイルを用いた message queue 実現方式 (※ 詳細後述) の都合上、 priority 値に制限が掛かってしまうのは仕方がない。
sparse file として実現するならば、 理論上はファイルサイズ上限で表現可能な範囲で priority 上限を許容できる筈ではある。
ストレージの利用効率上、 未使用/使用済みな領域に対するブロック解放が必要になるが、 ブロック境界とメッセージの消費状況が上手く噛み合わないと、 単に実装を複雑にしただけ (= ブロック解放効果無し) で終わる可能性も……
4.7.3. POSIX Message Queues (続き)
Solaris Internals の原文では、 あたかも「メッセージ最大サイズ」や「メッセージ最大数」を mq_setattr() で動的に変更可能な記述が見られる:
If necessary, you can increase the message size and number of messages by using msg_setattr(3R), ....
しかし mq_setattr() で動的に変更可能な設定は、 ブロッキングの設定・解消 (O_NONBLOCK 設定) のみで、 それ以外の設定は mq_open() による message queue 初期生成時 でのみ可能 (この振る舞いは POSIX 標準仕様による規定通り)。
4.7.3. POSIX Message Queues (続き)
[4.7.3/5]
"message queue header" 構造体 mqhdr_t のフィールド値のいくつか (e.g. mq_headpp, mq_tailpp) は、 "pointer 値" と呼称されていますが、 共有モードで mmap(2) されるファイル上にデータ構造が構築される = プロセス毎に配置先アドレスが異なる可能性があることから、 参照先領域のアドレスではなく、 "mqhdr_t 先頭からのオフセット値" を保持しています。
※ データファイルのレイアウトに関しては、 t キーで表示モードを切り替えて地の文を参照のこと。
POSIX message queue データファイル内のレイアウトは以下の通り。 管理情報は冒頭の mqhdr_t 相当領域に保持される。
"offset" は mqhdr_t 相当領域先頭を起点とした値。 "不変" は "当該 message queue 生成から破棄まで値が固定" を意味する。
+---------------- <<= 0
| mq_totsize (EOF までの総データ量 = mmap 対象サイズ)
+----------------
| mq_maxsz (メッセージ毎の最大サイズ)
+----------------
| mq_maxmsg (最大メッセージ数)
+----------------
| mq_maxprio (最大優先度数)
+----------------
:
+----------------
| mq_freep (利用可能なメッセージ書き出し領域の offset/随時更新)
+----------------
| mq_headpp (先頭メッセージ参照用配列領域の offset/不変)
+----------------
| mq_tailpp (末尾メッセージ参照用配列領域の offset/不変)
+----------------
:
+---------------- <<= mq_headpp = sizeof(mqhdr_t)/不変
|
| 優先度毎の先頭メッセージ参照用配列
| 領域サイズ: sizeof(uint64_t) * mq_maxprio
| 格納値: メッセージ毎領域の配列中要素への offset
|
+---------------- <<= mq_tailpp/不変
|
| 優先度毎の末尾メッセージ参照用配列
| 領域サイズ: sizeof(uint64_t) * mq_maxprio
| 格納値: メッセージ毎領域の配列中要素への offset
|
+---------------- <<= mq_freep の初期値
|
| メッセージ毎領域の配列
| 領域サイズ: (sizeof(msghdr_t) + mq_maxsz) * mq_maxmsg
|
+---------------- <<= EOF = mq_totsize/不変
"メッセージ毎領域" のレイアウトは以下の通り。
+---------------- <<= 0 | msg_next (リスト中の次の要素の offset 値) +---------------- | msg_len (メッセージデータ長) +---------------- <<= sizeof(msghdr_t) | 有効なメッセージデータ +---------------- <<= sizeof(msghdr_t) + msg_len | 未使用領域 +---------------- <<= sizeof(msghdr_t) + mqhdr_t.mq_maxsz
mmap(2) 結果の先頭アドレス (= mqhdr_t 相当領域の先頭アドレス値) mqhp からアクセス対象領域の実アドレスを算出するために、 以下のようなマクロが定義されている
- MQ_PTR(mqhp, offset): 冒頭から offset 位置
- HEAD_PTR(mqhp, prio): 優先度 prio の先頭メッセージ参照保持位置
- TAIL_PTR(mqhp, prio): 優先度 prio の末尾メッセージ参照保持位置
読み出し対象メッセージに対応する msghdr_t の オフセット値 を currentp とした場合、 有効なメッセージデータの先頭アドレスは &(MQ_PTR(mqhp, currentp)[1]) で表現できる。
4.7.3. POSIX Message Queues (続き)
型 mqd_t として定義される値を "message (queue) descriptor" と呼んでいて、 以下のように定義されている。
- OpenSolaris (OI 5.11 151) では typedef void *mqd_t;
- Linux 4.15.0 (Ubuntu 18.04 LTS) では typedef int mqd_t;
Solaris では (多分 Linux でもそうだと思われるが) 実質的には 構造体 mqhdr_t へのポインタ値。 但し、エラー時の -1 値の場合は除く。
4.7.3. POSIX Message Queues (続き)
[4.7.3/6]
"message descrip tor" (の参照先 mqhdr_t 領域) では、 権限情報や (活性確認用の) マジックナンバー等を管理しています。 mq_dn 構造体 ("message descrip tion" 構造体) は、 プロセス毎の設定である "blocking 動作の有無" を保持しています。
descrip tor と descrip tion は全く別モノなので注意。
というか、なんでこんな紛らわしい命名にしたんだろう? :-<
英語ネイティブな人にとってはわかりやすいのかな?
4.7.3. POSIX Message Queues (続き)
[4.7.3/7-12]
message queue の利用開始における処理手順を説明します。
- mq_open() 契機で /tmp 配下にロック用ファイルを生成 (詳細は 4.7.1. の地の文で説明)
- message queue の新規作成時は、 キュー毎の最大メッセージ数やメッセージ総数を設定
- 権限管理ファイルの作成と権限検証を実施
- 最大メッセージ数やメッセージ総数から算出される "総サイズ" を元に、 データファイルのサイズを ftruncate(3C) で設定
- message queue が生成済みの場合、 データファイルの読み込みを実施
4.7.3. POSIX Message Queues (続き)
作成済み message queue に対する mq_open() における手順:
- データファイルを open(2)
- データファイル冒頭の mqhdr_t 相当領域から mq_totsize フィールド値を read(2) で読み出し
- データファイルの内容を共有モードで mmap(2) (読み込み領域指定に必要なファイルサイズは mq_totsize 値を使用)
データファイルは初期生成時に ftruncate() で mq_totsize 値相当にサイズ設定済みなので、 サイズ取得は lstat(2) でも良さそうな気がするが……
作成済み message queue に対する mq_open() 時は、 データファイルに対する read(2) 後に、 同一ファイルディスクリプタを使って mmap(2) を実施している。
XPG7 の mmap() ドキュメント では、 引数で指定するオフセット値 off が、 ファイル先頭からの値なのか、 ファイルディスクリプタ fd の現行アクセス位置相対なのか、 明確な言及がない。
「明確な言及がない」=「ファイル先頭からの値」との解釈が妥当ではあるが、 一応念の為 Solaris での mmap(2) 実装を確認してみた。
mmap(2) のカーネル側実装に相当する smmap_common() (usr/src/uts/common/os/grow.c で定義) 周辺での処理手順は以下の通り:
- 引数 fd からカーネル側管理情報を保持する file_t 領域のアドレスを取得 (以下 fp)
- fp から当該ファイルの vnode_t アドレスを取得 (以下 vp)
- 以下の値を引数に VOP_MAP() 呼び出しを実施
- fd から導出された vp
- mmap(2) 呼び出しの際の off 値 (as pos 引数)
以上の手順を踏まえた上で、 以下の理由から、 指定ファイルディスクリプタの現行アクセス位置が mmap(2) でのマッピング範囲に影響しないことが確認できた。
- ファイルディスクリプタ毎のアクセス位置は、
VOP_MAP() 呼び出しに影響を与えない
- 引数として直接使用されてはいない
- 引数 pos にも影響を与えていない
- ファイルディスクリプタ毎のアクセス位置は、 各プロセス毎に保持する file_t 領域の f_offset フィールドの管理対象であり、 vnode_t からは参照不可
4.7.3. POSIX Message Queues (続き)
[4.7.3/13]
"message queue 生成済み" のケースは、 message queue 新規作成後に、 他のプロセスから mq_open() されるケースに相当します。
"他のプロセス" は、 "新規作成後に mq_unlink() せずに終了したプログラムの再実行" も含む。
4.7.3. POSIX Message Queues (続き)
[4.7.3/14-17]
- プロセス毎管理用の mqdes_t 構造体を malloc し、 message queue のデータファイル (= mqhdr_t 相当) を共有モードで mmap(2)
- message queue descriptor ファイル (= データファイル) を open(2) (create あり) + mmap(2) + close(2)
- message queue 新規作成時は、 領域初期化のために内部関数 mq_init() を実行 (プロセス間連携のための semaphore の初期化含む)
- 初期化が完了したら mq_init() から mq_open() に復帰
手順 6 と 7、手順 8 と 9 を分けて記述する意味はあるのか? :-<
4.7.3. POSIX Message Queues (続き)
message descrip tion の保持領域向けに /tmp 配下に作成したファイルは、 共有モードで mmap(2) した直後に unlink(2) されており、 他のプロセスとは共有できない (しない) 状態になっている。 (詳細は t キーで表示モードを切り替えて地の文を参照のこと)。
以下 mq_open() の実装コード (in usr/src/lib/libc/port/rt/mqueue.c) での DSCN ファイル操作部分の抜粋。
/* * DSCN ファイルを open (不在時は create) */ if ((fd = __pos4obj_open(path, MQ_DSCN_TYPE, O_RDWR | O_CREAT, ...)) < 0) goto out; /* * DSCN ファイルを **unlink** * ⇛ ファイルシステム上では他プロセスから見えなくなる */ (void) __pos4obj_unlink(path, MQ_DSCN_TYPE); /* * open(2) によるプロセスからの参照は残っているので * DSCN ファイルの mmap は可能 * ⇛ DSCN ファイルへの参照を +1 */ if ((ptr = mmap64(NULL, sizeof (struct mq_dn), PROT_READ | PROT_WRITE, MAP_SHARED, fd, (off64_t)0)) == MAP_FAILED) goto out; /* * プロセスからの DSCN ファイルへの参照を -1 * ⇛ mmap による参照のみが残る */ (void) __close_nc(fd);
4.7.3. POSIX Message Queues (続き)
message descrip tion 領域確保の際に、 非共有 モードとか anonymous メモリでの mmap(2) とか、 それこそ malloc(3C) 経由でのヒープ領域確保とかにしてないのは何故?
以前は "プロセス間で blocking/non-blocking 設定が共有" な実装になっていて、 段階的に実装を移行した名残とか?
4.7.3. POSIX Message Queues (続き)
POSIX message queue では、 「キューからのメッセージ取り出しのみ」の挙動を "read-only" と表現しているが、 「メッセージの取り出し」は「管理データの改変」を伴うので、 mq_open() に対する動作指定が "read-only" であっても、 対象データファイルに対する open(2) 時モード指定は O_RDWR であり、 mmap(2) 時権限指定は PROT_READ|PROT_WRITE となる。
4.7.3. POSIX Message Queues (続き)
[4.7.3/18-22]
message queue が確立された後は、 mq_send() や mq_receive() でメッセージが送受信可能になります。
- mq_send() においてメッセージ書き出し可否 (= 空き領域の有無) を判定するために、 mqhdr_t 領域の mq_notfull フィールドの semaphore をチェック
- 非ブロックな message queue への mq_send() の場合は sem_trywait() で可否を判定 (= 「空き無し」ならエラー復帰)
- それ以外の場合は sem_wait() で空きができるまで休止
- 空きができた (= mq_notfull から値取得成功) なら操作用排他を獲得
mqhdr_t の mq_freep フィールド値の使用方法は、 少々トリッキーになっている。
空き無し状態の mq_freep フィールド値には 0 が使用されるので、 mq_freep を起点にしたリスト走査の終端判定には mq_freep 値をそのまま使用可能。
mq_freep フィールド値が 0 の場合に MQ_PTR(mqhp, mqhp->mq_freep) は空き領域 ではない 不正なアドレスを返すが、 メッセージ送信時は事前に sem_wait() で領域空き待ちを行うので、 そもそも mq_freep が 0 の場合に MQ_PTR() 適用は発生しない = 「空き領域有り」の状態なら MQ_PTR() 使用は安全。
4.7.3. POSIX Message Queues (続き)
[4.7.3/23]
メッセージ到着を signal で通知する機能は、 System V message queues には無い POSIX message queues 固有の機能です (mq_notify() で自プロセスを通知対象として登録/解除)
4.7.3. POSIX Message Queues (続き)
[4.7.3/24-25]
- signal 通知待ちプロセスがある場合 (= mq_sigid への値設定あり)、 メッセージ待ちでブロック中のプロセスがなければ、 mq_send() はメッセージ追加を signal で通知
- 内部関数 mq_putmsg() において、 空き領域リスト (= mqhdr_t 領域の mq_freep フィールドの参照先) から切り離したメッセージ毎領域にメッセージデータを書き込み、 該当優先度のメッセージ一覧末尾に追加
4.7.3. POSIX Message Queues (続き)
[4.7.3/26-31]
mq_receive() でのメッセージ受信手順は以下の通り。
- mqhdr_t 領域の mq_notempty semaphore フィールドで 未読メッセージの有無を判定
- 非ブロックな message queue なら sem_trywait() で受信可否を判定 (= 「未読無し」ならエラー復帰)
- それ以外は sem_wait() で新規メッセージ到着まで休止
- 未読メッセージあり (= mq_notempty の値取得成功) なら操作用排他を獲得
- 内部関数 mq_getmsg() で先頭未読メッセージの読み出し (+ 当該メッセージ保持領域を "空きリスト" に追加)
4.7.3. POSIX Message Queues (続き)
[4.7.3/32]
mq_receive() による未読メッセージの読み出しは、 mq_send() 時に指定する priority 値が高い順 (同一 priority のものは先着順) から実施されます。
4.7.3. POSIX Message Queues (続き)
Solaris Internals 原文では、 あたかも mq_receive(3R) 呼び出しの際にも、 priority 指定が可能であるかのように記述されているが:
A message priority can be specified in the mq_send(3R) and mq_receive(3R) calls
mq_receive() の引数 msg_prio は、 読み出したメッセージの priority 値の確認用であり、 読み出しメッセージの priority 値指定用ではない。
以下 XPG7 の mq_receive() ドキュメント より引用:
If the argument msg_prio is not NULL, the priority of the selected message shall be stored in the location referenced by msg_prio.
4.8. Solaris Doors
[4.8/1-2]
Solaris Doors は、 同一ホスト上で動作している別プロセスが door_create(3C) API 経由で公開している関数を、 別プロセスからプロセス越しに door_call(3C) API で呼び出す機能です。
Solaris Doors (a.k.a. "door API") は Solaris 2.6 で導入され、 共有ライブラリ libdoor.so のリンクにより利用可能です。
4.8. Solaris Doors (続き)
Solaris Internals 原文では door API を 3X セクション扱いしているが、 少なくとも OpenIndiana ベースの環境では 3C セクション扱いになっている。
ちなみに、 原文の紙版では 3DOOR セクション扱いになっている模様 :-)
4.8.1. Doors Overview
[4.8.1/1]
door_call(3C) API 呼び出しでは、 適切な door を特定するために、 ファイルによる対象 door の抽象化を行っています。
図 4.6 は "illustrates broadly" とのことだが、 broadly (おおまか) にも程がある気が……
4.8.1. Doors Overview (続き)
[4.8.1/2]
サーバ側は door_creaet(3C) API による "door 生成" 経由で、 自プロセス内の関数を他プロセスの door クライアントに公開します。 生成された door は、 fattach(3C) API によりファイルに紐づけされ、 クライアントは当該ファイルのファイルディスクリプタ経由で door_call(3C) API を発行します。
4.8.2. Doors Implementation
※ 実装詳細に関しては地の文章を参照
とりあえずは Solaris Internals の 本文記述は無視 して、 Solaris の実装コードベースで door IPC を使用した際の処理フローを示す。
実装/定義の記述対象ファイル:
ユーザ空間実装
CPU 非依存な実装:
- usr/src/lib/libc/port/threads/door_calls.c (aka "door_calls.c")
- usr/src/lib/libc/port/threads/scalls.c (aka "scalls.c")
CPU 固有の実装 (≒ システムコールの発行周り):
- usr/src/lib/libc/amd64/sys/door.s
- usr/src/lib/libc/i386/sys/door.s
- usr/src/lib/libc/sparc/sys/door.s (aka "door.s")
以降の説明における記述は SPARC 向け実装に基づくもの。
カーネル空間実装
door IPC 固有の定義/実装:
- usr/src/uts/common/sys/door.h
- usr/src/uts/common/sys/door_data.h
- usr/src/uts/common/sys/door_impl.h
- usr/src/uts/common/fs/doorfs/door_sys.c (aka "door_sys.c")
関連機能の実装:
- usr/src/uts/common/disp/shuttle.c (aka "shuttle.c")
- shuttle_swtch()
- shuttle_resume()
- for thread_onproc()
- usr/src/uts/sparc/v9/ml/lock_prim.s (aka "lock_prim.s")
- usr/src/uts/intel/ia32/ml/lock_prim.s
door IPC でサービスを提供するプロセス側での初期化処理:
door_create(3C) (in door_calls.c) の呼び出し
実質的な処理実体は door_create_cmn() (in door_calls.c) 側で実装。
システムコール SYS_door (+ サブコード DOOR_CREATE) を発行
※ システムコール SYS_door 発行は、 実際には door.s で定義される __door_xxxxx() 関数群 (xxxxx 部分はサブコードに相当する create, call 等々) を経由するが、 以降の説明では説明簡略化のために、 これらの関数呼び出しに関する言及は省略する (但し __door_return() に関しては詳細記述あり)。
カーネル内処理 door_create_common() (in door_sys.c) の呼び出し
実際には以下の関数 (いずれも door_sys.c で定義) を経由
- doorfs(): システムコール SYS_door の受け付け関数
- door_create(): パラメータチェック/応答値設定
以後の説明ではシステムコール SYS_door 発行時において、 実処理関数の呼び出しの際に doorfs() を経由する旨の言及は省略。
door filesystem 向けの VNODE インスタンスを生成
- door_node_t 領域 (by kmem_zalloc())
- vnode_t 領域 (by vn_alloc())
※ エンドユーザから見えるファイルシステムツリー上には対応を持たない
当該 VNODE に対応する file descriptor (fd) を生成
by falloc() (in usr/src/uts/common/os/fio.c)
システムコール SYS_door (+ サブコード DOOR_CREATE) から復帰
戻り値は door filesystem の VNODE インスタンスに対応する fd
door_create_server() (in door_calls.c) の呼び出し
同ファイル内で定義されている、 関数ポインタを参照するグローバル変数 door_server_func 経由での呼び出し。
当該変数は door_server_create(3C) 経由で変更可能。
※ 公開 API と内部関数の名前の紛らわしいこと…… :-<
thr_create(3C) で新規スレッドを生成
door_create(3C) 呼び出し元には、 このスレッド生成の後に復帰。
呼び出し元には、 door filesystem の VNODE インスタンスに対応する fd を返却。
既存の filesystem の名前空間上で fattach(3C) を実施
当該ファイルパス毎に name filesystem の VNODE が生成される。
単一 door filesystem VNODE を複数のファイルパスに fattach(3C) することが可能。
※ 簡略化のため以降の説明では name filesystem 周りの話は省略
実際に door IPC 経由で処理要求の受け付け/実行を行うには、 thr_create(3C) で作成された新規スレッド上において、 以下の手順で処理要求の待ち受け状態に到達している必要がある。
door_create_func() (in door_calls.c) の呼び出し
door_return(3C) (in door_calls.c) の呼び出し
引数には全て NULL/0 を指定
__door_return() (in door.s) の呼び出し
door_return(3C) において、 スタック周りの諸々の処理を行っているが、 基本的な挙動とは無関係なので省略
システムコール SYS_door (+ サブコード DOOR_RETURN) を発行
カーネル内処理 door_return() (in door_sys.c) の呼び出し
当該スレッドの door 処理に関する情報を初期化
by door_my_server()
kmem_zalloc() で確保した door_data_t 領域を kthread_t.t_door に設定。
要求発行元の確認
door_call(3C) 発行元スレッドの kthread_t が格納される、 kthread_t.t_door 参照先の door_data_t.d_server.d_caller を確認 (以下 caller と呼称)。
直前の door_my_server() 呼び出しで初期化されたばかりなので、 この時点では NULL。
現行スレッドを処理実施スレッド待ちプールに追加
by door_release_server()
d_active, d_caller 等の 0/NULL クリア含む
処理実施スレッドの待ちプールには、 サーバプロセス内の door 横断で共有されるプールの他に、 door 毎に占有されるプールが存在する。
基本動作には関係ないのでプール管理周りの詳細は省略。
shuttle_swtch() の呼び出し
この時点では caller == NULL なので、 door_return() における if (caller) に対する else 節ブロック (= shuttle_swtch() の呼び出しのみ) が実行される。
現行スレッドは sleep 化。
door IPC 経由で処理要求を発行する、 いわゆる "クライアント" 側での処理手順は以下の通り。
door_call(3C) (in scall.c) の呼び出し
システムコール SYS_door (+ サブコード DOOR_CALL) を発行
カーネル内処理 door_call() の呼び出し
指定 fd から door VNODE の引き当て
by door_lookup()
処理実施スレッド待ちプールからスレッドを割り当て
by door_get_server()
door_call(3C) 呼び出し時の引数を処理実施スレッドのスタックに転送
by door_args()
現行スレッド (kthread_t) を呼び出し元スレッドとして記録
処理実施スレッドの kthread_t.t_door 参照先の door_data_t.d_server.d_caller に現行スレッドを設定
shuttle_resume() で処理実施スレッドの実行を再開
door_get_server() 内での thread_onproc() (in lock_prim.s) により、 この時点で処理実施スレッドが既に CPU に紐付けされている (筈)。
そのため、 現行スレッド (= door_call() 実行側) を sleep 状態に設定した上での swtch_to() により、 CPU の処理対象が処理実施スレッドに (即座に) 切り替わる (筈)。
swtch_to() のコメント曰く:
like swtch(), but switch to a specified thread taken from another CPU.
カーネルでの kthread_t 管理データ上は、 要求発行側/要求処理側のスレッドが都度 sleep 状態になる体裁だが、 実際には同一 CPU コア上で "要求発行 ⇛ 要求受理" (復路での "応答返却 ⇛ 応答受理" も) が実行されることになるので、 実質は "カーネル空間経由のオーバヘッド以外はほぼ関数呼び出し" 的な感じになる (筈)。
ちなみに swtch_to() は creat(2) みたいな "シンボル名の長さ制限由来の綴省略" なのかと思ったけど、 ひょっとしたら swtch が C 言語予約語の switch と被らないように綴省略されているので、 それを踏襲したのかな?
上記手順で発行された door IPC 要求は、 処理実施スレッドの実行を再開させる。
shuttle_swtch() 呼び出しから復帰
復帰先は、 新規スレッドにおける door_return(3C) 由来のカーネル内処理 door_return()
呼び出し側引数取り出し/スタック周りの変換処理
by door_server_dispatch()
処理実施スレッドのスタック上には以下のデータが格納される。
- cookie (of door_create(3C))
- data_ptr (of door_call(3C))
- data_size (of door_call(3C))
- desc_ptr (of door_call(3C))
- desc_size (of door_call(3C))
- pc (= server_procedure of door_create(3C))
- servers (= 処理実施スレッドの待ちプールの非空性)
- info as door_info
※ door_call(3C) 契機のカーネル内処理 door_call() で発行される door_args() と、 上記の door_server_dispatch() で実施される処理 (= door_return(3C) 契機のカーネル内処理 door_return() で発行) の間での、 パラメータ周りの処理における役割分担に関しては要確認
システムコール SYS_door (+ サブコード DOOR_RETURN) から復帰
処理実施スレッドの待ちプールが空 (= !servers 成立) の場合、 door_depletion_cb() (in door_calls.c) 経由で処理実施スレッドの追加生成を実行。
スレッド生成をユーザ空間で実施するのは、 プロセス終了契機でのスレッド破棄を容易にするためかな?
NFS 関連のサービス (nfsd, nlmd, mountd 等々) 周りも、 これに類する実装になっていたような記憶が……
スタックから取り出した情報を元に処理実施関数に制御遷移
処理実施関数の引数を取り出す (+ out レジスタに設定)
- cookie (of door_create(3C))
- data_ptr
- data_size
- desc_ptr
- desc_size
取り出した pc に jmpl 命令で間接サブルーチンコール
戻り先アドレスは jmpl 命令 (+ 遅延スロット) の後ろ
要求に対する処理が完了した際に、 処理実施スレッドは以下の手順でクライアントに応答を返却する。
処理実施関数で door_return(3C) を実行
__door_return() の呼び出し
※ 実行時の制御遷移フロー的には、 door_return(3C) の延長で __door_return() から呼び出された (体裁の) 処理実施関数が、 処理終了時に再び door_return(3C) 経由で __door_return() を呼び出していることになる。
無限に再起呼び出しされている (体裁の) __door_return() だが、 以下のような振る舞いをすることで、 スタック溢れが発生しないようになっている。
- door_return(3C) からの __door_return() 呼び出しは、 末尾呼び出しの最適化によりスタック消費が無い
- __door_return() においてはスタックの追加消費がない
- レジスタ退避領域確保の save 命令実行がない
- 局所変数向けスタック領域確保がない
システムコール SYS_door (+ サブコード DOOR_RETURN) を発行
カーネル内処理 door_return() の呼び出し
当該スレッドの door 処理情報を確保
※ 前回の door_return(3C) 呼び出しの延長で既に初期化済み
応答データ内容を door_call(3C) 実行側プロセス空間に書き出し
by door_result()
メモリ領域確保や fd 変換含む
書き出し先スタックを所有するスレッドは、 door_call(3C) 契機のカーネル内処理 door_call() において、 処理実施スレッド (= 現行スレッド) の kthread_t.t_door 参照先の door_data_t.d_server.d_caller に記録されている。
現行スレッドを door 処置待ち受けスレッド一覧に追加
by door_release_server() (※ door_data_t.d_server.d_caller 等の NULL クリア含む)
door_call(3C) 実行側スレッドの処理を再開
by shuttle_resume()
※ 実行パス的には if (caller) の then ブロック相当
このまま次の door_call(3C) による処理要求を待つ。
要求発行側スレッドは以下の要領で要求応答を受け取る。
カーネル内処理 door_call() での shuttle_resume() から復帰
応答内容を door_call(3C) 呼び出し元のアドレス空間に転送
メモリ領域確保含む
カーネル内処理 door_call() を終了
システムコール SYS_door (サブコード DOOR_CALL) から復帰
door_call(3C) から復帰
door IPC における処理フローの概要をシーケンス図にしたものを示す。 視認性向上のため、呼び出しの入れ子等をある程度簡略化している。
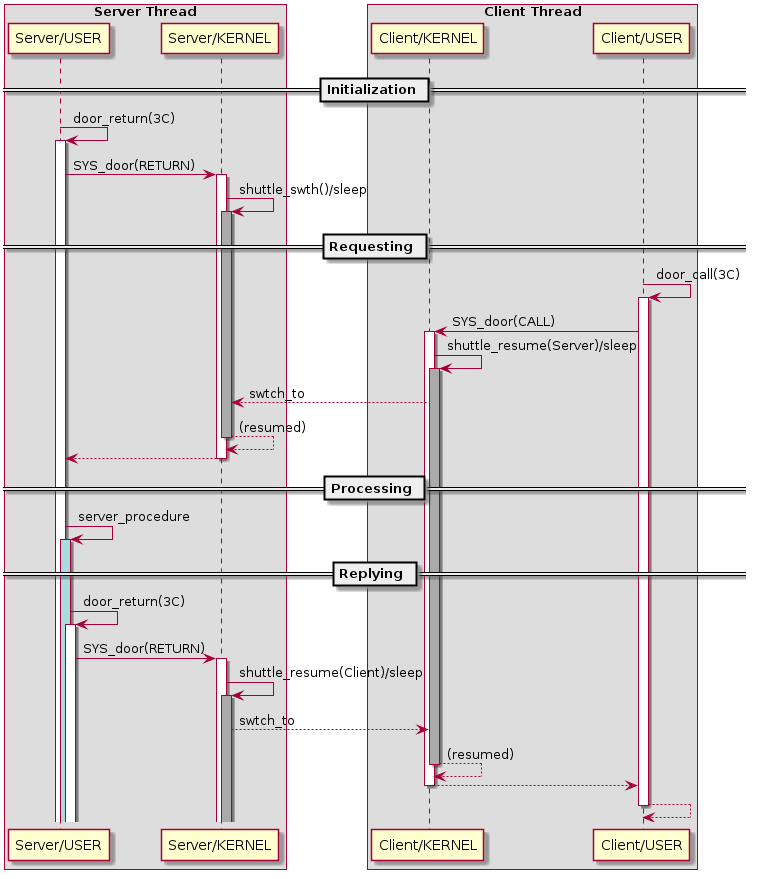
door IPC 処理シーケンス概要
活性区間は以下の方針で色分けしてある:
- 白: Solaris が提供する実装による実行部分
- 灰: スレッドが休眠状態にあることを示す
- 青: エンドユーザによる機能実装 (= door IPC サーバ処理)
4.8.2. Doors Implementation (続き)
[4.8.2/1-2]
Solaris Doors は疑似ファイルシステム doorfs としてカーネル内で実装されています。 ユーザプロセスにおける個々の door (= 通信チャネル) は、 ファイルディスクリプタとして管理されています。
Solaris Doors 実装における主要なデータ構造を、 図 4.7 に示します。
4.8.2. Doors Implementation (続き)
[4.8.2/3]
単一プロセスで複数の door サービスを提供可能にするため、 door_create(3C) 実施毎に door_node_t 領域が確保され、 proc_t.p_door_list を起点とする単方向リストで管理されます。 door サーバスレッドの初期化契機で確保される door_data_t 領域には、 door_call(3C) 呼び出しで指定された引数等の格納領域もあります。
4.8.2. Doors Implementation (続き)
図 4.7 の間違い (1):
公開ソースの実装における door_data_t は、 以下の二つの構造体を包含する構造体として定義されている。
- サービス利用側 ("client") に関する情報を保持する door_client_t
- サービス提供側 ("server") に関する情報を保持する door_server_t
Solaris Internals の図版では、 上記二つの構造体のフィールドが順不同でフラットに列挙されている (e.g. d_args や d_dv, d_kernel は client 向けだが、 d_caller や d_servers は server 向け)
4.8.2. Doors Implementation (続き)
図 4.7 の間違い (2):
door_node_t.door_data は、 door_create(3C) 呼び出しの際にユーザプロセスから指定される door 毎 cookie 値 に相当する値を保持するフィールドであり、 door_data_t を参照するフィールド ではない 。
door_data_t は thread_t.t_door からは参照されるが、 door_node_t からの参照は無い。
4.8.2. Doors Implementation (続き)
図 4.7 の補足 (1):
door_node_t.door_target は、 当該 door サーバのプロセスに相当する proc_t を参照する。
原文図版では矢印表記の起点が曖昧。
4.8.2. Doors Implementation (続き)
図 4.7 の補足 (2):
各データ領域の多重度:
- door_node_t は door 毎に 1 つ
- door_data_t は door の server スレッド毎 (= kthread_t 毎) に 1 つ
4.8.2. Doors Implementation (続き)
図 4.7 の補足 (3):
door サービスを提供するスレッドは、 door_create(3C) の attributes 引数に対する DOOR_PRIVATE フラグ指定の有無に応じて、 異なるスレッドプールから割り当てられる。
- 指定あり: door_node_t.door_servers 起点のプール (= "door 毎")
- 指定なし: proc_t.p_server_threads 起点のプール (= "process 毎")
プールにおける第二要素以降の kthread_t は、 先頭要素の kthread_t.t_door から参照される door_data_t.d_servers 経由で順次リンクされる。
原文図版では:
- プール先頭の kthread_t への矢印表記の起点が曖昧
- server 相当の kthread_t から door_data_t への参照がない
- door_data_t.d_servers から (server 相当の) kthread_t への参照がない
4.8.2. Doors Implementation (続き)
door IPC 実装における多くの箇所で、 kthread_t ** 型として定義されている ktp 変数は、 Solaris 実装における旧来の命名規約的には ktpp になる筈。
微妙に規約違反していることで、 * 付きでの評価や、 & 併用式の値の代入等の際に、 "あれ?これってポインタ値?ポインタ変数のアドレス?" と混乱してしまう :-<
4.8.2. Doors Implementation (続き)
door_data_t に関する疑問 (1):
door_data_t が door_client_t と door_server_t の共用体ではなく、 両者を包含する構造体として定義されているのはなぜか?
推測: door サーバとして動作しているスレッドが、 他の door サービスに対するクライアントになる可能性があるためでは?
4.8.2. Doors Implementation (続き)
door_data_t に関する疑問 (2):
door_client_t と door_server_t を個別に参照するフィールドを kthread_t に設けなかったのはなぜか?
推測: door IPC を使うスレッド数は限定的であるため、 kthread_t 構造体のメモリ消費が増加するよりは、 door_data_t 構造体によるメモリ消費が増加する方を選んだのでは?
4.8.2. Doors Implementation (続き)
[4.8.2/4]
libdoor.so が提供する door_create(3C) の呼び出しにより、 カーネル内処理 door_create() が以下の処理を実施します。
4.8.2. Doors Implementation (続き)
[4.8.2/5-9]
- door_node_t および vnode_t 相当のメモリ領域を確保し、 各フィールドを初期化する
- door_node_t.door_target に当該プロセスの proc_t アドレスを設定する
- door_node_t.door_pc にサービス提供関数のアドレス (Program Counter) を設定する
- door_node_t.door_flags に door_create(3C) の attributes 引数値を設定する
- vnode_t に VFS 対応の上で必要な初期化を行う
4.8.2. Doors Implementation (続き)
Solaris Internals 原文では "door vnode" に対して "part of the door_node structure" と表現しているが、 実際には他の filesystem 実装と同様に、 vnode_t と door_node_t はそれぞれ独立した領域として定義されている。
⇛ Solaris 2.6 当時は一体化されていた模様
手順 5 では vnode_t の初期化に関して説明しているが、 手順 1 における "initializes several fields of door_node and the door vnode" で網羅済みな気が……
⇛ Solaris 2.6 時点での実装コードをそのまま文章化しているとのタレコミあり
4.8.2. Doors Implementation (続き)
[4.8.2/10-13]
- proc_t.p_door_list を起点とする管理リストに door_node_t 領域を追加し、 door IPC 向けのファイルディスクリプタを falloc() で確保する
- カーネル内処理 door_create() での処理が終了したので、 ユーザ空間に制御を戻す
- サービス提供関数を実行するスレッドが必要なので、 スレッドライブラリとのリンクが必須
- サービス提供関数を実行するスレッドを thr_create(3C) で生成
4.8.2. Doors Implementation (続き)
[4.8.2/14-15]
サービス提供スレッドでは door_create_func() 経由で door_return(3C) を呼び出す
door_return(3C) のカーネル内処理では、 プロセッサの制御を door_call(3C) 呼び出し側スレッドに遷移させ、 サービス提供スレッドを休止状態にした上で、 次の呼び出しに備えて待ち行列に追加する
kthread_t.t_door が NULL の場合 (= 初回実行時) は、 door_data_t 領域を確保して初期化する。
4.8.2. Doors Implementation (続き)
door_data_t 領域は、 引数 create_if_missing が非ゼロ値で以下の関数が呼ばれた際に、 内部共通処理関数 door_my_data() によって確保される。
- door_my_server(): サービス提供スレッド側で呼び出される
- door_my_client(): サービス利用スレッド側で呼び出される
4.8.2. Doors Implementation (続き)
[4.8.2/16-17]
カーネル内 door_return() 処理における door_data_t 領域確保 (= door_my_server() 呼び出し) 以降のいくつかの処理は、 door_call(3C) に対する引数や戻り値等々に関する処理なので、 詳細に関しては後ほど改めて言及します。
door 機能の初期化に関して、 カーネル内 door_return() における残りの処理は以下の通り。
4.8.2. Doors Implementation (続き)
[4.8.2/18-20]
現行スレッド (= door_return(3C) 呼び出しスレッド) を door_call(3C) に対するサービス提供用スレッド一覧に登録するために、 door_release_server() を呼び出す
door_release_server() では、 サービス提供スレッド一覧へのエントリ追加や、 サービス提供スレッドの空き待ちで休止している door_call(3C) 呼び出しへの kcondvar 経由での通知を実施する
door 初期化は基本的にこの時点で完了
カーネル処理における shuttle_swtch() 処理は shuttle 同期機構を用いて当該スレッドを休止状態にする
4.8.2. Doors Implementation (続き)
Solaris Internals 原文における、 旧来の "歴史的" 実装ベースの説明に対する補足 - その 1:
原文では proc_t.p_server_threads を用いた管理 (= "process 毎" プール) にのみ触れているが、 先述したように最新版では door_node_t.door_servers を用いた管理 (= "door 毎") も行っている。
4.8.2. Doors Implementation (続き)
Solaris Internals 原文における、 旧来の "歴史的" 実装ベースの説明に対する補足 - その 2:
原文で触れている kcondvar door_cv は、 グローバルな領域として extern 宣言こそ存在するものの、 変数領域の実体が存在しないし、 そもそも door_cv を利用する処理自体が既に存在していない。
process 毎プールあるいは door 毎プール管理が導入された段階で、 スレッド空き待ちで休止中のスレッドへの通知には、 プール毎の kcondvar を用いる実装に変更されたものと思われる。
4.8.2. Doors Implementation (続き)
[4.8.2/21-22]
状態変数 (condition variable) や sleep queue を用いた典型的な実行制御では kernel dispatcher が、 mutex や reader/writer lock のような同期機構では tunrstiles が実行制御を管理します。
shuttle 同期機構は、 dispatcher 関連のオーバヘッド無しに、 あるカーネルスレッドから別のカーネルスレッドへと、 プロセッサの実行対象を切り替え可能です。
4.8.2. Doors Implementation (続き)
Solaris Internals 原文曰く:
Shuttle objects are currently used only by the doors subsystem in Solaris
4.8.2. Doors Implementation (続き)
[4.8.2/23]
shuttle 同期機構により休止中のカーネルスレッドは、 TS_SLEEP 状態にあり、 T_WAKEABLE フラグが設定されている。 (※ shuttle_t の各フィールドの状態詳細は割愛)
4.8.2. Doors Implementation (続き)
[4.8.2/24-26]
shuttle の話題から door 初期化の話に戻ります:
- door_call(3C) 呼び出しが並走した場合、 並走する呼び出しスレッドの数だけ、 サービス提供用スレッドが生成される (初期状態は 1 スレッドのみ生成)
- door ライブラリのスレッド生成におけるデフォルト挙動は "標準設定の bound 且つ detached なスレッドの生成"
4.8.2. Doors Implementation (続き)
door グループ毎のスレッドプール管理するとか、 プール毎にスレッド数上限を設定するなど、 スレッド生成方針に関してカスタマイズが必要な場合は、 door_server_create(3C) 経由で サービス提供スレッド生成関数を登録する。
4.8.2. Doors Implementation (続き)
[4.8.2/27]
以上で door サーバの初期化が完了しました。 サービス提供用スレッドプールに連なるスレッドは shuttle_swtch() 経由で休止状態にあり、 いつでもサービス機能を提供可能です。
4.8.2. Doors Implementation (続き)
[4.8.2/28]
door サーバを初期化したアプリケーションは、 他プロセスから door 機能を呼び出すためのファイルを準備するために、 open(2) および fattach(3C) API を用います。
4.8.2. Doors Implementation (続き)
[4.8.2/29-30]
STREAM や STREAM-based pipe の関連付けと同様に、 ファイルシステム名前空間における特定のファイルに対して fattach(3C) API によって door デスクリプタが関連付けされることで、 同一ホスト上の他のプロセスから容易に IPC が利用できます。
fattach(3C) は疑似ファイルシステム namefs を利用して実装されています。 通常のファイルシステムのマウント先がディレクトリである一方、 namefs は非ディレクトリに対してマウントされます。
4.8.2. Doors Implementation (続き)
[4.8.2/31-32]
door サーバの初期化後、 公開されている door サービスは door_call(3C) 経由で利用可能です。
- カーネル処理 door_call() は door_data_t のためのメモリ領域を確保し、 当該スレッドの kthread_t.t_door に設定
4.8.2. Doors Implementation (続き)
door_call(3C) 呼び出しスレッドが、 別の door に対するサービス提供スレッドの場合、 当該スレッドの kthread_t.t_door は待ち pool への投入時に初期化済みなので、 割り当て済みの door_data_t 領域の d_client フィールドを利用する。
4.8.2. Doors Implementation (続き)
[4.8.2/33-34]
door_call(3C) の引数 door_arg が非 NULL の場合、 当該領域をカーネル側 door_data_t.d_client.d_args 領域に複製 (この時点では door_arg 参照先領域内容の複製のみ)
door_call(3C) の引数 params への NULL 指定は、 "引数情報無し" と同時に "戻り値無し" も意味するので、 door_data_t.d_client.d_noresults に 1 が設定される
カーネル処理 door_lookup() において、 door デスクリプタから対応する door_node_t を引き当てる
4.8.2. Doors Implementation (続き)
補足 (1):
door_call(3C) で指定されるファイルディスクリプタは、 fattach(3C) で生成された namefs の vnode に対応するので、 door_lookup() での door_node_t 引き当てでは VOP_REALVP() (実体は nm_realvp()) を利用している。
補足 (2):
原文は vnode_t が door_node_t に包含されている前提の記述だが、 先述したように現行実装の door_node_t は vnode_t を包含 していない
4.8.2. Doors Implementation (続き)
[4.8.2/35-36]
- サービス実行スレッドを引き当てるために、 カーネル処理 door_get_server() を呼び出す
- door_get_server() は、 処理スレッドをスレッドプールから取り除いた上で、 thread_onproc() を使って実行状態を TS_SLEEP から TS_ONPROC に変更する
4.8.2. Doors Implementation (続き)
[4.8.2/37-38]
呼び出しスレッド側の door_data_t.d_client.d_args が保持する引数情報を、 引数情報の種別毎にカーネル内部に取り込む
各種状態設定 (※ 詳細は割愛) が完了した後、 door_get_server() が割り当てたサービス提供側スレッド側に、 shuttle_resume() によって制御を移行
shuttle_resume() 呼び出しには、 引き当てられたサービス提供スレッドの kthread_t が指定される
4.8.2. Doors Implementation (続き)
door_call(3C) の引数 door_arg 経由で、 サービス提供側スレッドに対して以下の情報を渡すことができる。
- data_ptr: データ (サイズ指定付き)
- desc_ptr: ファイルディスクリプタ (複数指定可能)
4.8.2. Doors Implementation (続き)
door_call(3C) の door_arg に指定された "引数" をプロセス間で遣り取りするために必要な以下処理は door_args() が実施している。
- データの遣り取りには、プロセス空間の間で当該領域の複製が必要
- ファイルディスクリプタの遣り取りには、 クライアント側プロセスのファイルディスクリプタ (= 整数値) から、 対応する vnode_t を引き当てた上で、 サーバプロセス側で当該 vnode_t へのファイルディスクリプタ割り当てが必要
4.8.2. Doors Implementation (続き)
ファイルの読み書きに関しては、 アクセス権限のチェックは open(2) 時しか実施されない (属性変更等は都度権限チェックが走る可能性あり)。
そのため、 ファイルディスクリプタの渡し元プロセスがアクセス権限を持っていれば、 渡し先プロセスにアクセス権限が無くても、 渡されたディスクリプタ経由で当該ファイルの読み書きが可能。
4.8.2. Doors Implementation (続き)
[4.8.2/39]
shuttle_resume() に指定された kthread_t に相当するスレッド (= door サービス提供スレッド) がプロセッサの制御を獲得し、 shuttle_resume() を呼び出したスレッド (= door サービス利用側スレッド) を休止状態にする必要があります。
4.8.2. Doors Implementation (続き)
[4.8.2/40-42]
- shuttle_resume() は、 現時点での実行中スレッド (= shuttle_resume() 呼び出しスレッド) を shuttle 同期機構によって休止状態にする
- 未処理シグナル等があれば、現行スレッド上で実行
- swtch_to() 呼び出しにより、 サービス提供スレッド側にプロセッサの制御を移行する
4.8.2. Doors Implementation (続き)
[4.8.2/43-45]
- サービス提供スレッド上で door 作成時に指定した関数が実行される
- サービス提供スレッドは door_return(3C) 呼び出しにより、 呼び出し元に戻り値を返す
- カーネル処理 door_return() は、 呼び出し元スレッド (= door_call(3C) 呼び出し元) に戻り値を返すための処理を行い、 当該スレッドをスレッドプールに戻した上で、 プロセッサの制御を呼び出し元スレッドに戻すために、 shuttle_resume() 呼び出しを行う
4.8.2. Doors Implementation (続き)
[4.8.2/46]
サービス提供側処理の完了を待たずに door_call() 呼び出しから復帰した場合は、 その原因 (e.g. signal 受理や exit() 呼び出し等々) を特定した上で、 サービス提供側スレッドに SGICANCEL を送信します。 サービス提供側スレッドが signal 受理や exit() 呼び出し等々で中断された場合は、 door_call() は中断され、 呼び出し元には EINTR エラーが通知されます。
4.9. MDB Reference
MDB に関する説明なので割愛
Chapter 4: Interprocess Communication
~ END ~